400 128 6709

行业新闻
 发布时间:2023-06-15
发布时间:2023-06-15 点击次数:
点击次数: 在 AI 绘画领域,阿里提出的 Composer 和斯坦福提出的基于 Stable diffusion 的 ControlNet 引领了可控图像生成的理论发展。但是,业界在可控视频生成上的探索依旧处于相对空白的状态。
相比于图像生成,可控的视频更加复杂,因为除了视频内容的空间的可控性之外,还需要满足时间维度的可控性。基于此,阿里巴巴和蚂蚁集团的研究团队率先做出尝试并提出了 VideoComposer,即通过组合式生成范式同时实现视频在时间和空间两个维度上的可控性。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

前段时间,阿里巴巴在魔搭社区和 Hugging Face 低调开源了文生视频大模型,意外地受到国内外开发者的广泛关注,该模型生成的视频甚至得到马斯克本尊的回应,模型在魔搭社区上连续多天获得单日上万次国际访问量。
Text-to-Video 在推特
VideoComposer 作为该研究团队的最新成果,又一次受到了国际社区的广泛关注。


VideoComposer 在推特
事实上,可控性已经成为视觉内容创作的更高基准,其在定制化的图像生成方面取得了显着进步,但在视频生成领域仍然具有三大挑战:
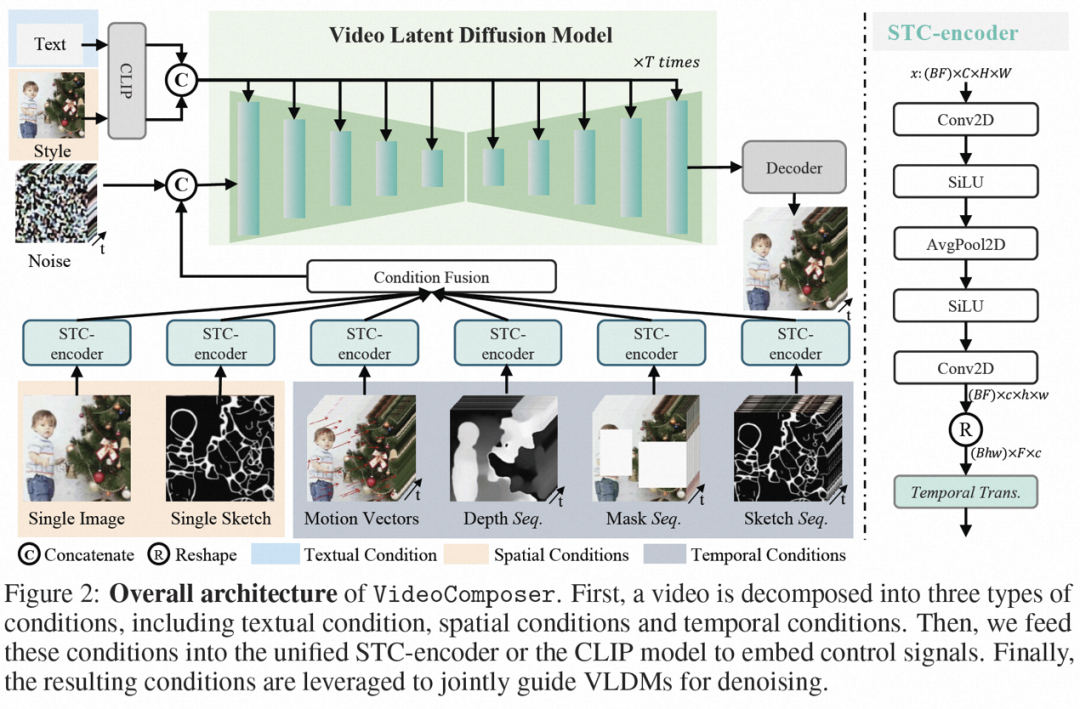
在此之前,阿里巴巴提出的 Composer 已经证明了组合性对图像生成可控性的提升具有极大的帮助,而 VideoComposer 这项研究同样是基于组合式生成范式,在解决以上三大挑战的同时提高视频生成的灵活性。具体是将视频分解成三种引导条件,即文本条件、空间条件、和视频特有的时序条件,然后基于此训练 Video LDM (Video Latent Diffusion Model)。特别地,其将高效的 Motion Vector 作为重要的显式的时序条件以学习视频的运动模式,并设计了一个简单有效的时空条件编码器 STC-encoder,保证条件驱动视频的时空连续性。在推理阶段,则可以随机组合不同的条件来控制视频内容。
实验结果表明,VideoComposer 能够灵活控制视频的时间和空间的模式,比如通过单张图、手绘图等生成特定的视频,甚至可以通过简单的手绘方向轻松控制目标的运动风格。该研究在 9 个不同的经典任务上直接测试 VideoComposer 的性能,均获得满意的结果,证明了 VideoComposer 通用性。
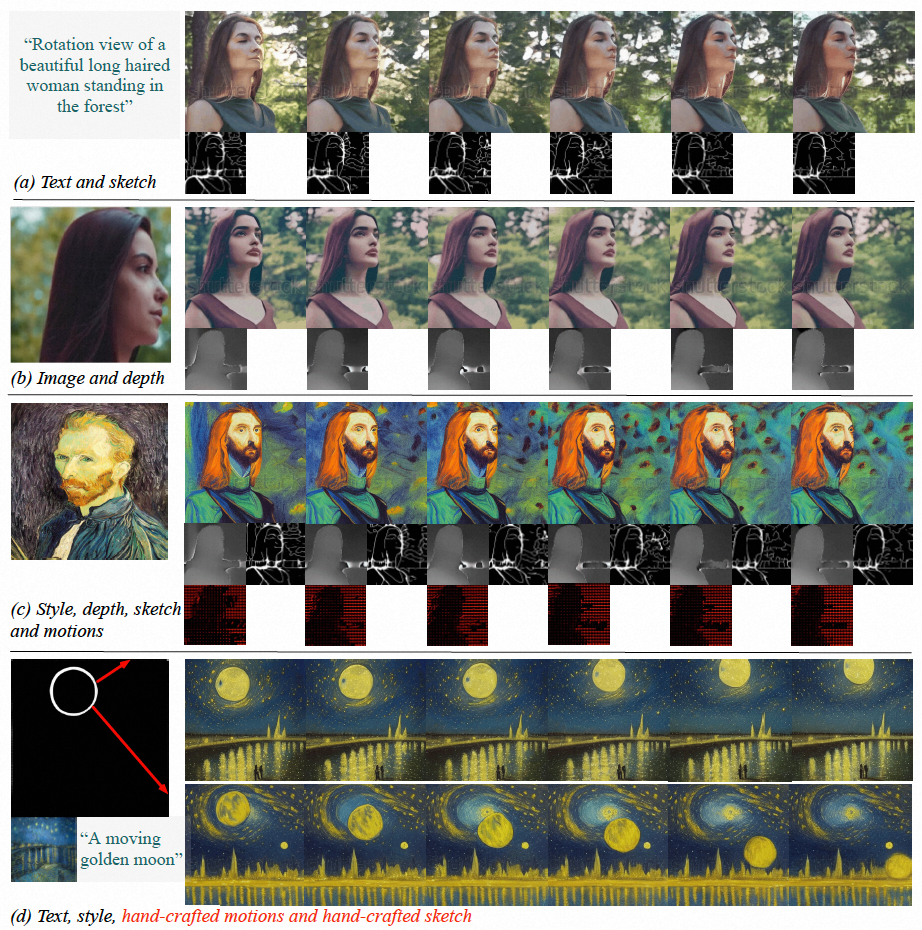
图 (a-c)VideoComposer 能够生成符合文本、空间和时间条件或其子集的视频;(d)VideoComposer 可以仅仅利用两笔画来生成满足梵高风格的视频,同时满足预期运动模式(红色笔画)和形状模式(白色笔画)
Video LDM
隐空间。Video LDM 首先引入预训练的编码器将输入的视频 。然后,在用预先训练的解码器 d 将隐空间映射到像素空间上去 扩散模型。为了学习实际的视频内容分布
免费 Chrome 扩展程序,使用 ChatGPT AI 生成电子邮件和消息。 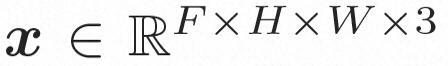
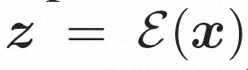 映射到隐空间表达,其中
映射到隐空间表达,其中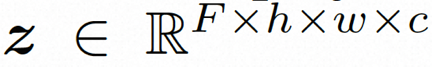
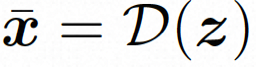 。在 videocomposer 中,参数设置
。在 videocomposer 中,参数设置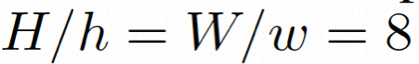
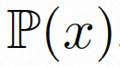
 ChatGPT Writer
ChatGPT Writer
 106
查看详情
106
查看详情
 ,扩散模型学习从正态分布噪声中逐步去噪来恢复真实的视觉内容,该过程实际上是在模拟可逆的长度为 T=1000 的马尔可夫链。为了在隐空间中进行可逆过程,Video LDM 将噪声注入到
,扩散模型学习从正态分布噪声中逐步去噪来恢复真实的视觉内容,该过程实际上是在模拟可逆的长度为 T=1000 的马尔可夫链。为了在隐空间中进行可逆过程,Video LDM 将噪声注入到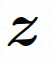
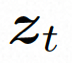
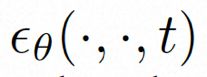
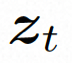
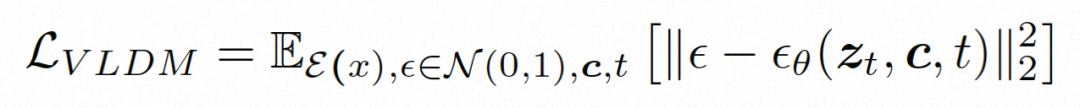
为了充分探索利用空间局部的归纳偏置和序列的时间归纳偏置进行去噪,VideoComposer 将 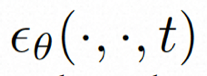
VideoComposer
组合条件。VideoComposer 将视频分解为三种不同类型的条件,即文本条件、空间条件和关键的时序条件,它们可以共同确定视频中的空间和时间模式。VideoComposer 是一个通用的组合式视频生成框架,因此,可以根据下游应用程序将更多的定制条件纳入 VideoComposer,不限于下述列出的条件:
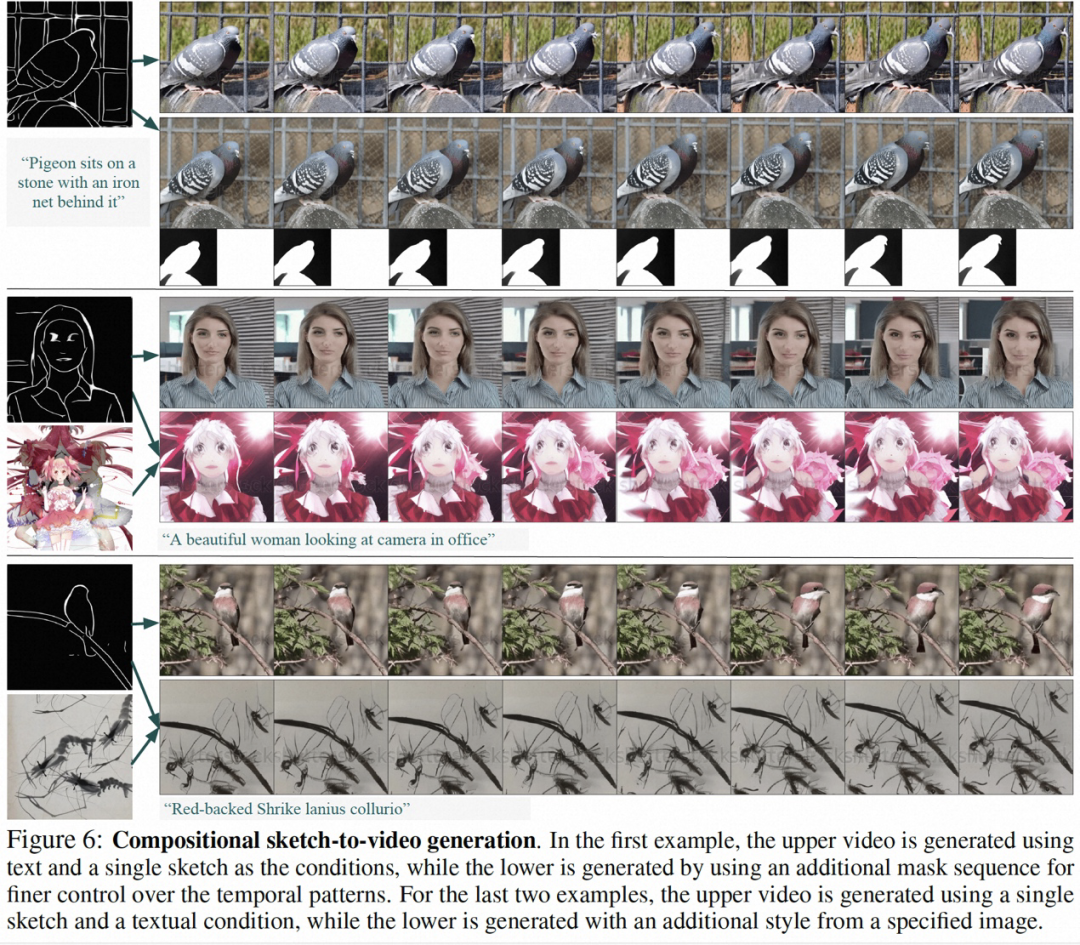
 草图序列可以提供更多的控制细节,从而实现精确的定制合成。
草图序列可以提供更多的控制细节,从而实现精确的定制合成。时空条件编码器。序列条件包含丰富而复杂的时空依赖关系,对可控的指示带来了较大挑战。为了增强输入条件的时序感知,该研究设计了一个时空条件编码器(STC-encoder)来纳入空时关系。具体而言,首先应用一个轻量级的空间结构,包括两个 2D 卷积和一个 *gPooling,用于提取局部空间信息,然后将得到的条件序列被输入到一个时序 Transformer 层进行时间建模。这样,STC-encoder 可以促进时间提示的显式嵌入,为多样化的输入提供统一的条件植入入口,从而增强帧间一致性。另外,该研究在时间维度上重复单个图像和单个草图的空间条件,以确保它们与时间条件的一致性,从而方便条件植入过程。
通过 STC-encoder 处理条件后,最终的条件序列具有与相同的空间形状,然后通过元素加法融合。最后,沿通道维度将合并后的条件序列与连接起来作为控制信号。对于文本和风格条件,利用交叉注意力机制注入文本和风格指导。
训练和推理
两阶段训练策略。虽然 VideoComposer 可以通过图像 LDM 的预训练进行初始化,其能够在一定程度上缓解训练难度,但模型难以同时具有时序动态感知的能力和多条件生成的能力,这个会增加训练组合视频生成的难度。因此,该研究采用了两阶段优化策略,第一阶段通过 T2V 训练的方法,让模型初步具有时序建模能力;第二阶段在通过组合式训练来优化 VideoComposer,以达到比较好的性能。
推理。在推理过程中,采用 DDIM 来提高推理效率。并采用无分类器指导来确保生成结果符合指定条件。生成过程可以形式化如下:
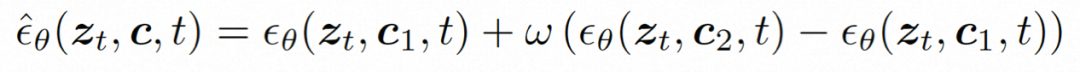
其中,ω 是指导比例;c1 和 c2 是两组条件。这种指导机制在两条件集合判断,可以通过强度控制来让模型具有更加灵活的控制。
在实验探索中,该研究证明作为 VideoComposer 作为统一模型具有通用生成框架,并在 9 项经典任务上验证 VideoComposer 的能力。
该研究的部分结果如下,在静态图片到视频生成(图 4)、视频 Inpainting(图 5)、静态草图生成生视频(图 6)、手绘运动控制视频(图 8)、运动迁移(图 A12)均能体现可控视频生成的优势。



公开信息显示,阿里巴巴在视觉基础模型上的研究主要围绕视觉表征大模型、视觉生成式大模型及其下游应用的研究,并在相关领域已经发表 CCF-A 类论文 60 余篇以及在多项行业竞赛中获得 10 余项国际冠军,比如可控图像生成方法 Composer、图文预训练方法 RA-CLIP 和 RLEG、未裁剪长视频自监督学习 HiCo/HiCo++、说话人脸生成方法 LipFormer 等均出自该团队。
以上就是时间、空间可控的视频生成走进现实,阿里大模型新作VideoComposer火了的详细内容,更多请关注其它相关文章!
# 并在
# 网站优化网站搜索排名
# 鹤壁seo推广营销公司
# 找营销推广公司合法吗
# 甘肃抖音seo优化布局
# 双流网站建设怎么收费
# 推广数字营销介绍语录
# 美容行业网站优化营销
# 无为网站优化价格
# seo补充案例
# 怎样开通推广网站
# 重庆
# 三种
# 视频
# 三大
# 转录
# 开源
# 可以通过
# 杜比
# 火了
# controlnet
# stable diffusion
# runway
# hugging face
# 阿里巴巴
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
讯飞听见会写“会议摘要”功能全面升级,AI更懂你的关注点
微软向美国政府提供GPT大模型,如何保证安全性?
微软 GitHub Copilot 编程助手被投诉:换口吻改写公共代码来躲版权
陈根:AI工具为游戏软件实时3D内容助力
苹果CEO库克:持续研究生成式人工智能技术
“技术+实践+生态”三箭齐发,京东方抢占物联网高地
Adobe旗下Illustrator引入生成式AI工具Firefly
小米首次曝光 64 亿参数的 MiLM-6B AI 大模型,或将应用于小爱同学
7大探索区域打造沉浸式玩乐“元宇宙” 昆明京东MALL未来科技探索官全城招募中
两型无人机完成交付!国家级机动观测业务正式启动
「社交达人」GPT-4!解读表情、揣测心理全都会
导演郭帆:人工智能应用可能会影响《流浪地球 3》的创作开发
Meta 开源 AI 语言模型 MusicGen,可将文本和旋律转化为完整乐曲
云深处科技绝影 Lite3 与 X20 四足机器人亮相
数字文明尼山对话 | 在东方圣城与AI潮流梦幻联动,看“智慧大脑”让数字山东更美好
人工智能在服务优化方面优缺点有哪些
今年,全球客服中心支出将增长 16.2%,迎接对话式 AI 的浪潮,根据 Gartner 报告
英伟达首席执行官黄仁勋:生成式 AI 时代「人类」会是新的编程语言
九号公司主导制定短途交通和送物机器人领域首个国际标准,标志着零的突破发布
网友自制 AI 版《流浪地球 3》预告片,登上 CCTV6
人工智能正在弥合认知和表达之间的鸿沟
用AI升级会议体验!思必驰多款会议产品亮相全球智博会!
猿力科技入选北京市通用人工智能产业创新伙伴计划
人工智能如何用于家庭安全
煤电“三改联动”需多措联动
中国移动副总经理高同庆:打造人工智能时代的智能服务运营新范式
如何获得元宇宙的第一个属于自己的空间
AI无法对传统文化符号进行解构和创新
中美陷入囚徒困境,人工智能变得不可控?可参考核不扩散条约规范
传Meta 2025年推出首款AR眼镜,采用军用级别材料,计划生产1000台
提高开发效率:AmazonCodeWhisperer与Amazon Glue的集成和生成式AI的应用
特斯拉 Optimus 人形机器人入驻北美门店,帮助提升汽车销量
干货满满,2025昆山元宇宙国际装备展等你来打卡!
大模型新品出现井喷,AI产业迎来新时代
一句话搞定数据分析,浙大全新大模型数据助手,连搜集都省了
无人机协助盐城交通执法的协同训练
消息称苹果 iPhone 15 系列健康应用将深度融合 AI 技术
商汤科技:元萝卜 AI 下棋机器人新品发布会 6 月 14 日举行
世界人工智能大会中西部县域数字就业中心组团亮相
V社谈AI制作游戏被ban:为确保开发者有素材所有权
生成式AI引路产业加速来袭,微美全息探索“AIGC+虚拟人”融合应用
科技数码圈的新物种 乐天派桌面机器人 AI +安卓+机器人 首发价1799元
云深处与昇腾CANN携手合作:开设ROS四足机器狗开发训练营
网易加速行业AI大模型应用,将覆盖100多个应用场景
五个IntelliJ IDEA插件,高效编写代码
先进技术在防止全球数据丢失方面的作用
阿里云连续两年进入Gartner云AI开发者“挑战者象限”
微软 Copilot 团队主管呼吁用户与 AI 交流时应使用恰当的礼貌用语
研究发现AI聊天机器人ChatGPT不会讲笑话,只会重复25个老梗
学界业界大咖探讨:AI对数字艺术创新的推动力
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表